ClickHouse是一个用于联机分析(OLAP)的列式数据库管理系统(DBMS)。
OLAP场景的关键特征
OLAP(OnLine Analysis Processing ,联机分析处理),核心思想就是建立多维度的数据立方体,以维度(Dimension)和度量(Measure)为基本概念,辅以元数据,实现可以钻取、切片、切块、旋转等灵活、系统、直观的数据展现。
它的特征有:
- 绝大多数是读请求
- 数据以相当大的批次(> 1000行)更新,而不是单行更新;或者根本没有更新。
- 已添加到数据库的数据不能修改。
- 对于读取,从数据库中提取相当多的行,但只提取列的一小部分。
- 宽表,即每个表包含着大量的列
- 查询相对较少(通常每台服务器每秒查询数百次或更少)
- 对于简单查询,允许延迟大约50毫秒
- 列中的数据相对较小:数字和短字符串(例如,每个URL 60个字节)
- 处理单个查询时需要高吞吐量(每台服务器每秒可达数十亿行)
- 事务不是必须的
- 对数据一致性要求低
- 每个查询有一个大表。除了他以外,其他的都很小。
- 查询结果明显小于源数据。换句话说,数据经过过滤或聚合,因此结果适合于单个服务器的RAM中
ClickHouse不适用的场景
- 不支持事务
- 不擅长按照主键进行粒度的查询(虽然支持)
- 不擅长按行删除数据(虽然支持)
ClickHouse的MergeTree引擎
MergeTree是ClickHouse最常用的表引擎,支持主键索引,数据分区,数据副本和数据采样等功能。

MergeTree的创建方式和存储方式
MergeTree写入一批数据时,数据会以数据片段的的形式写入磁盘,并且数据片段不可修改。为了避免数据片段过多,ClickHouse会通过后台线程,定期合并这些数据片段。
MergeTree的创建方式
1 | CREATE TABLE [IF NOT EXISTS] [db_name].table_name ( |
(1)PARTITION BY[选填]: 分区键,用于指定表数据以何种形式进行分区。分区键支持:单个列字段,元组的形式使用多个列字段,列表达式。不声明的话,ClickHouse会生成一个all的分区。
(2)ORDER BY[必填]: 排序键,指定在一个数据片段内,数据以何种标准排序。默认情况下主键和排序键相同。
(3)PRIMARY KEY[选填]: 主键,主键字段生成一级索引,用于加上表查询。MergeTree运行重复数据(ReplacingMergeTree可以去重)
(4) SAMPLE BY [选填]: 抽样表达式,声明数据的采样标准。声明了此配置项,主键的配置也有声明同样的表达式。
1 | ENGINE = MERGETREE() |
(5) SETTINGS: index_granularity表示索引的粒度,默认是8192。 MergeTree在默认情况下,每隔8192行数据才生产一条索引。
MergeTree的存储结构
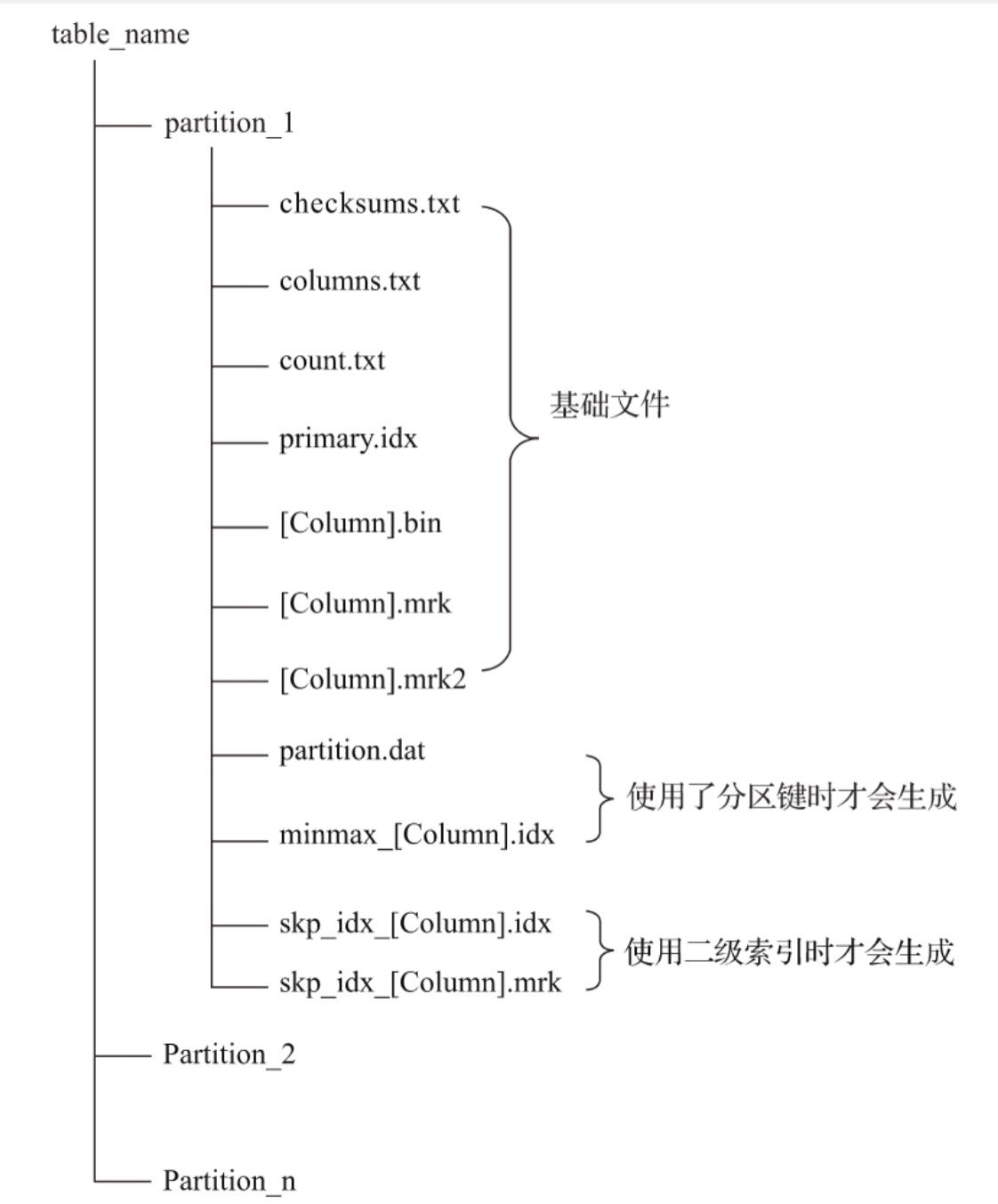
(1) partiton: 分区目录,数据以分区目录的形式存放。
(2) columns.txt:列信息文件
(3) count.txt: 计数文件,记录当前数据目录下数据的总行数。
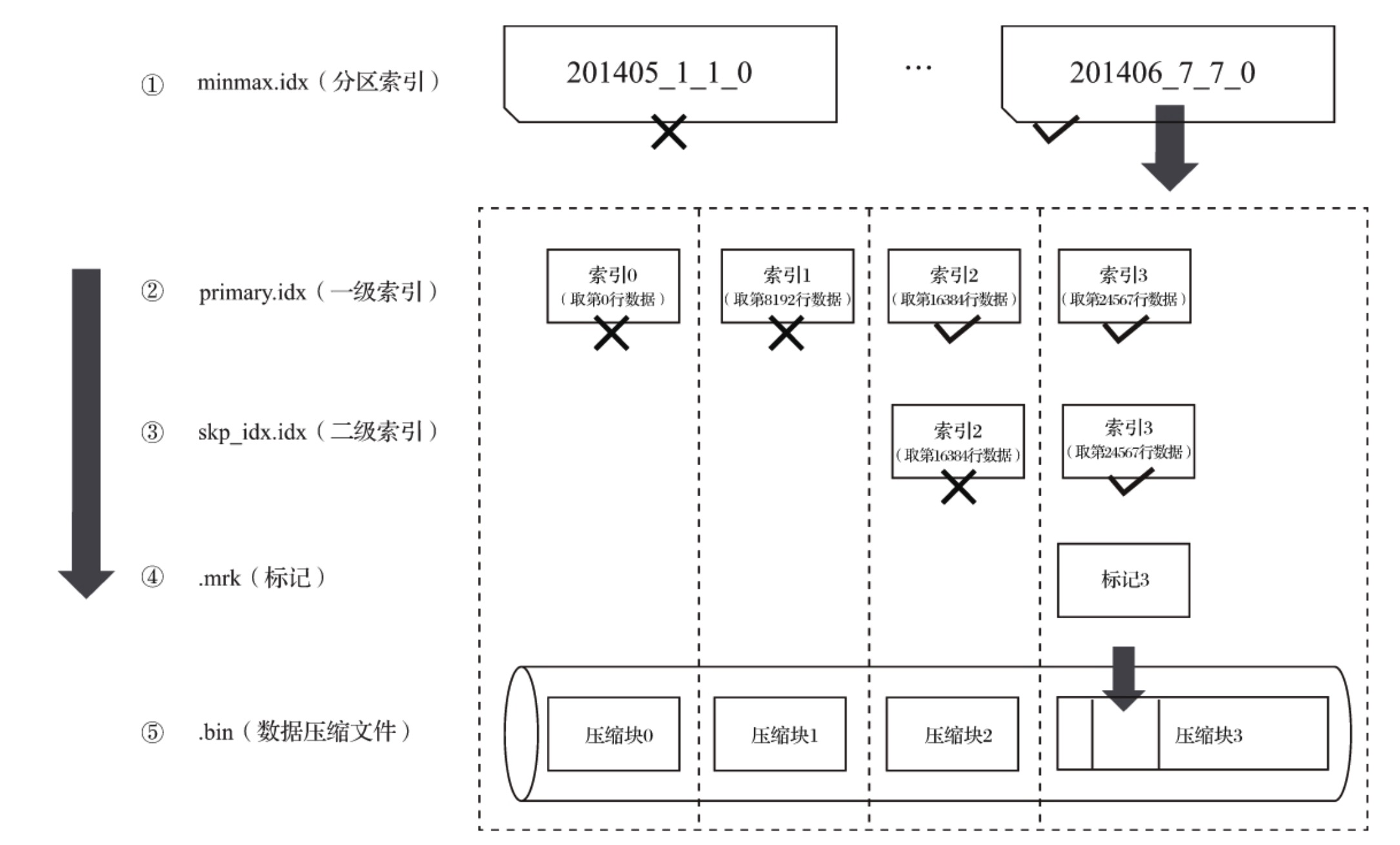
(4) primay.idx: 一级索引文件,是稀疏索引,以二进制形式存储。
(5) [Column].bin: 数据文件,存储某一列的数据,压缩格式存储,默认是LZ4压缩格式。每个列字段拥有独立.bin文件。
(6) [Column].mrk: 列字段标记文件,保存.bin中数据的偏移量信息。ClickHouse通过primay.idx稀疏索引,找到对应数据的偏移量信息(.mrk),然后通过偏移量直接从.bin文件中读取数据。
(7) [Column].mrk2: 使用了自适应大小的索引间隔,标记文件会以.mrk2命名。原理和.mrk相同。
(8) partition.dat和minmax_[Column].idx:使用了分区键就会生成。partiton.dat记录当前分区下,分区表达式最终生成的值。minmax索引记录当前分区下分区字段对应原始数据的最大值和最小值。这样方便查询时,跳过不必要数据分区,减少需要扫描的范围。
数据分区
MergeTree的分区由分区ID决定,分区ID由分区键的取值决定。
(1)不指定分区键:默认分区为all,所有数据都写入这个分区。
(2)使用整型(兼容UInt64,包括有符号整型和无符号整型):如果无法转化成日期类型YYYYMMDD格式,按照该整型的字符串形式取值。
(3)使用日期类型:按照日期类型YYYYMMDD格式化后字符串输出。
(4)其他类型:分区键类型不属于整型或者日期类型,例如Float64/String, 通过128Hash算法去Hash值作为分区ID的取值。
分区目录的命名规则
MergeTree的特点在于分区的合并,从分区的命名可以解读其合并逻辑。命名规则:
1 | PartitionID_MinBlockNum_MaxBlockNum_Level |
目录合并过程
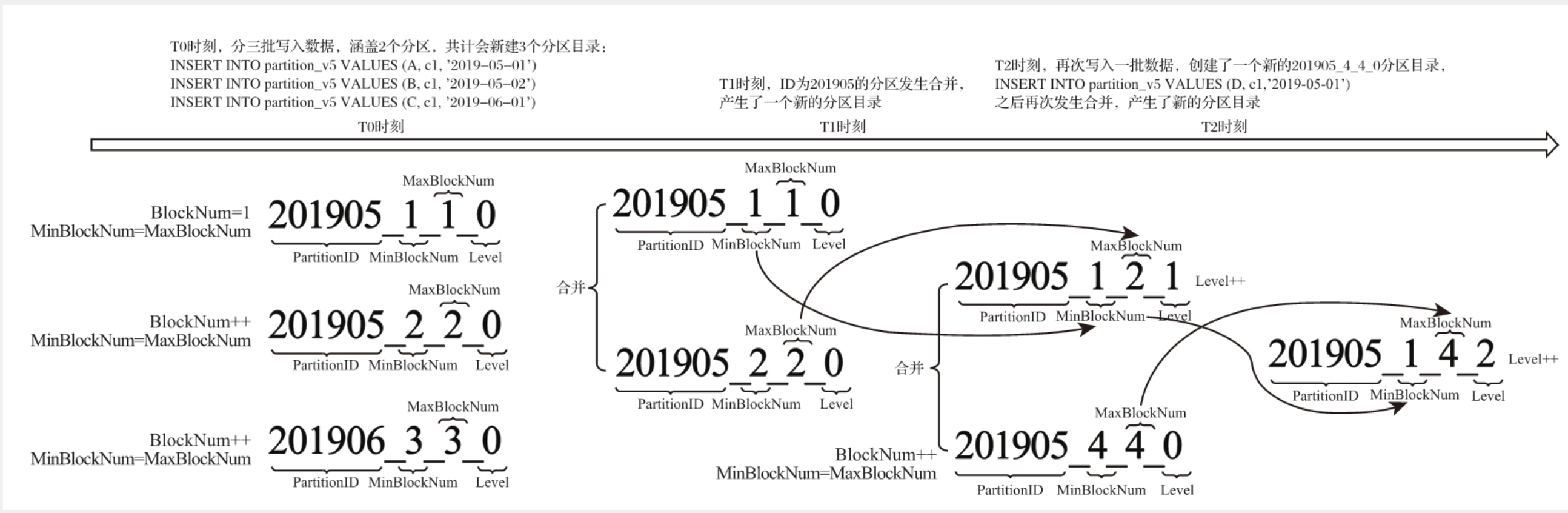
完整的目录合并过程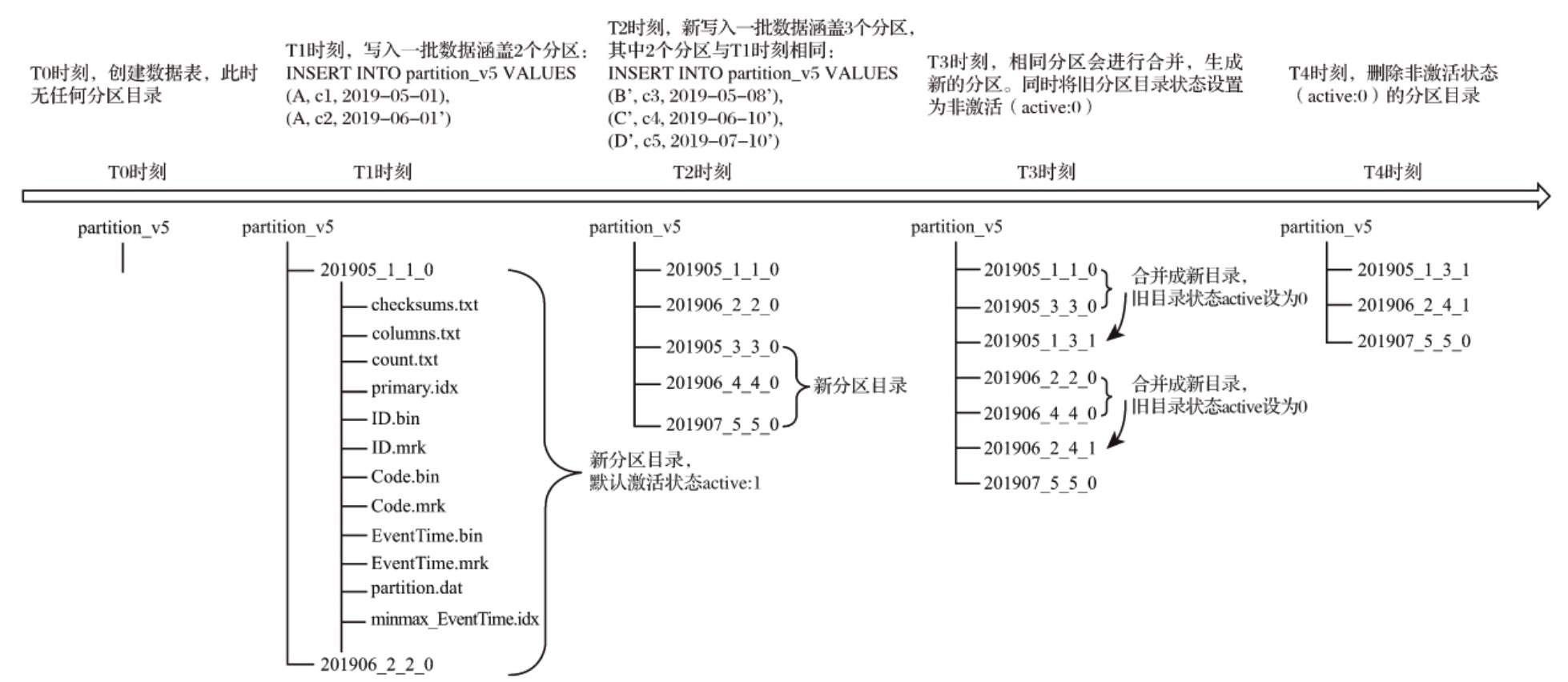
一级索引
MergeTree的主键使用PRIMARY KEY定义,按照index_granularity间隔,为数据表生成一级索引并保存至primary.idx文件,索引数据按照PRIMARY KEY排序。相比使用PRIMARY KEY,更常见的方式是通过ORDER BY指定主键。
数据存储
MergeTree中,数据是按列存储的,每个列字段有对应的.bin文件。按列独立存储可以更好地压缩数据,最小化数据扫描的范围。
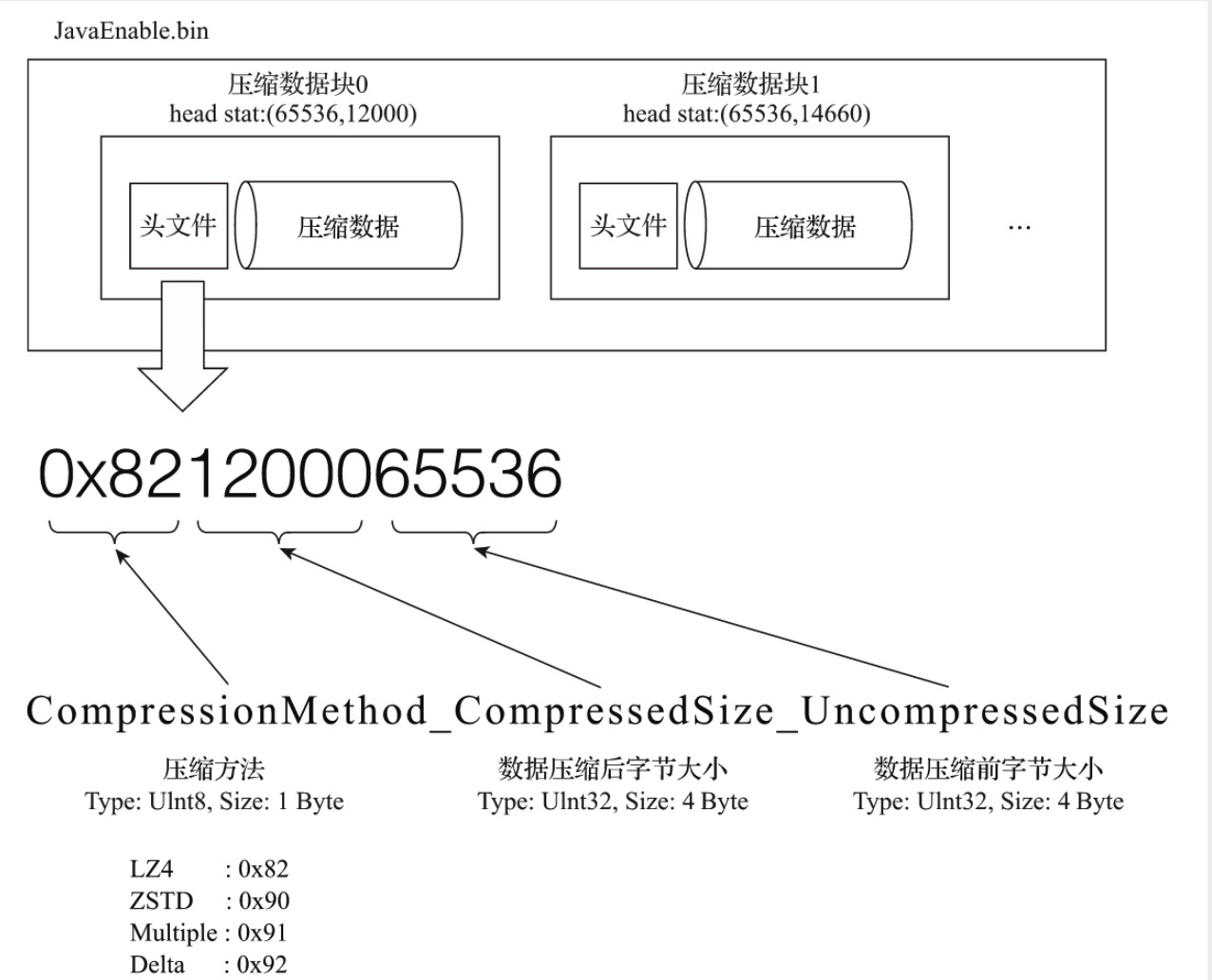
压缩数据块的逻辑
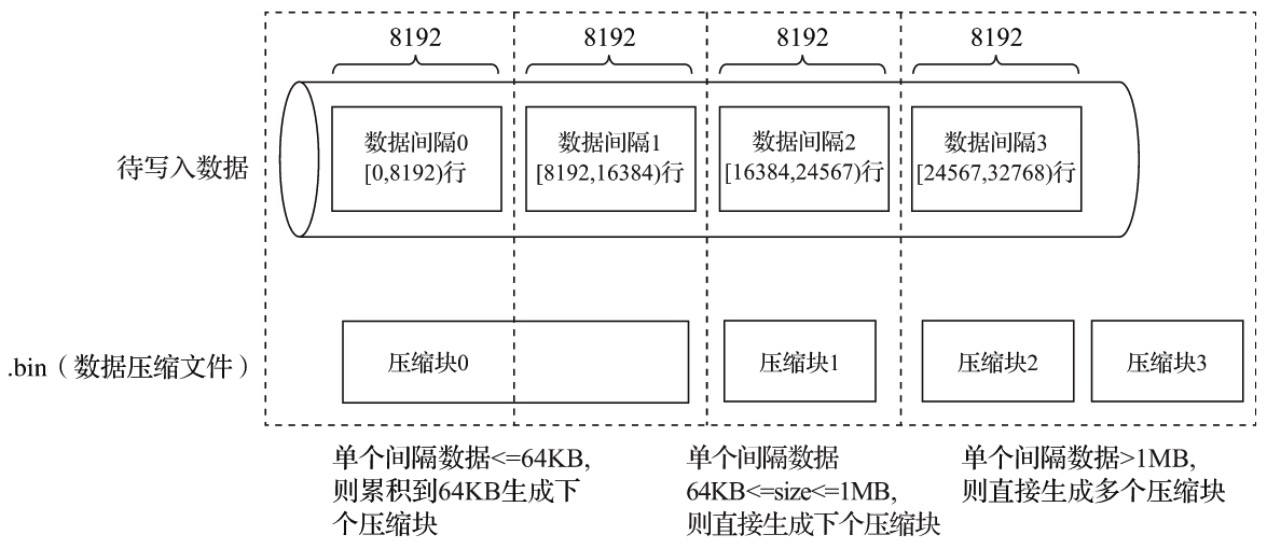
数据标记
数据标记和和索引区间是一一对齐的, 都按照index_granularity的间隔。
标记文件与.bin文件也一一对应,每一个[Column].bin文件都有一个对应的[Column].mrk文件,记录数据在.bin文件中的偏移量信息。
.mrk中每行数据,对应压缩文件中偏移量和解压缩文件中偏移量。
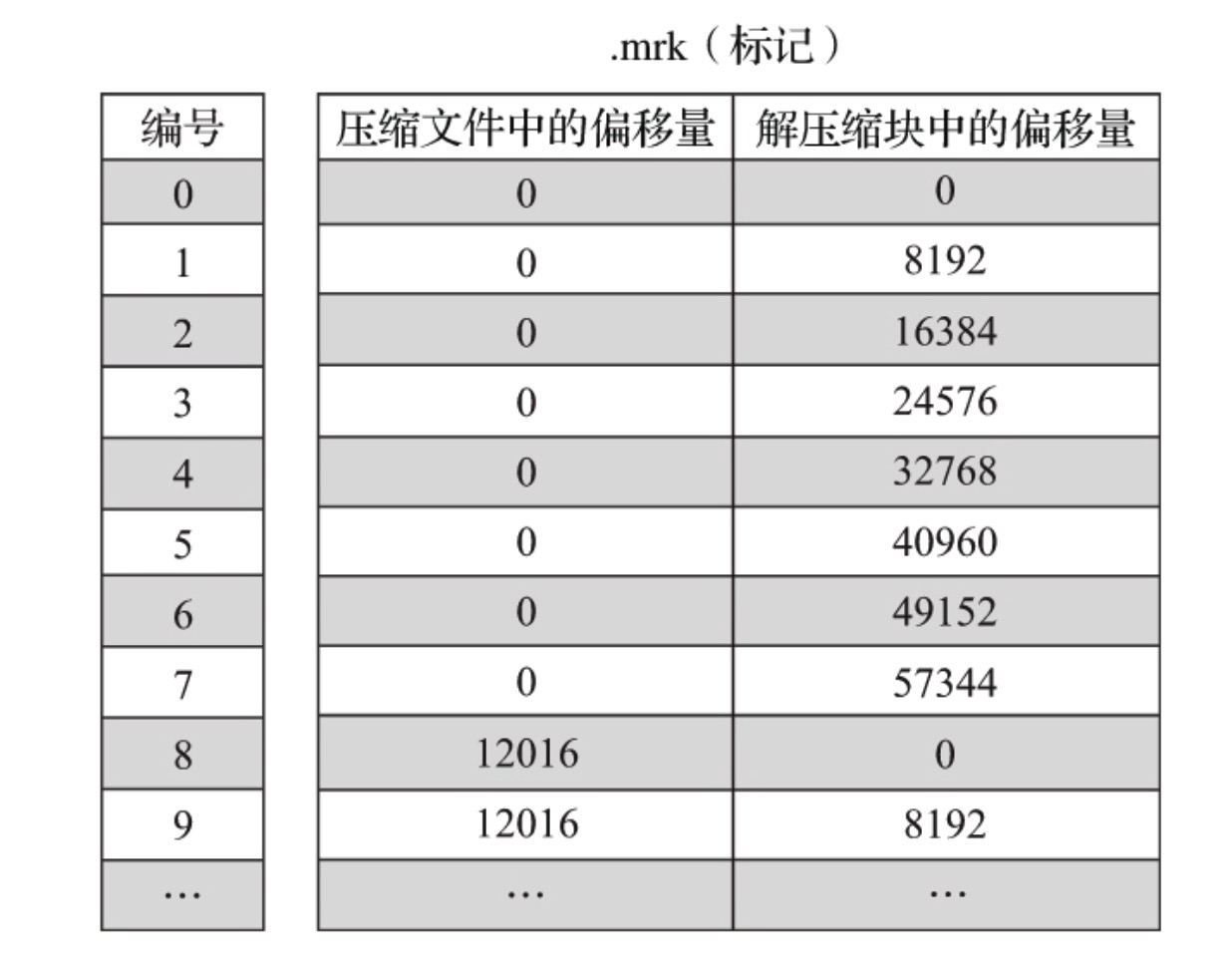
标记数据和一级索引数据不一样,它不能常驻内存,使用LRU缓存策略替换。
数据标记的工作方式
数据查找,分为读取压缩数据块,和读取数据两个步骤。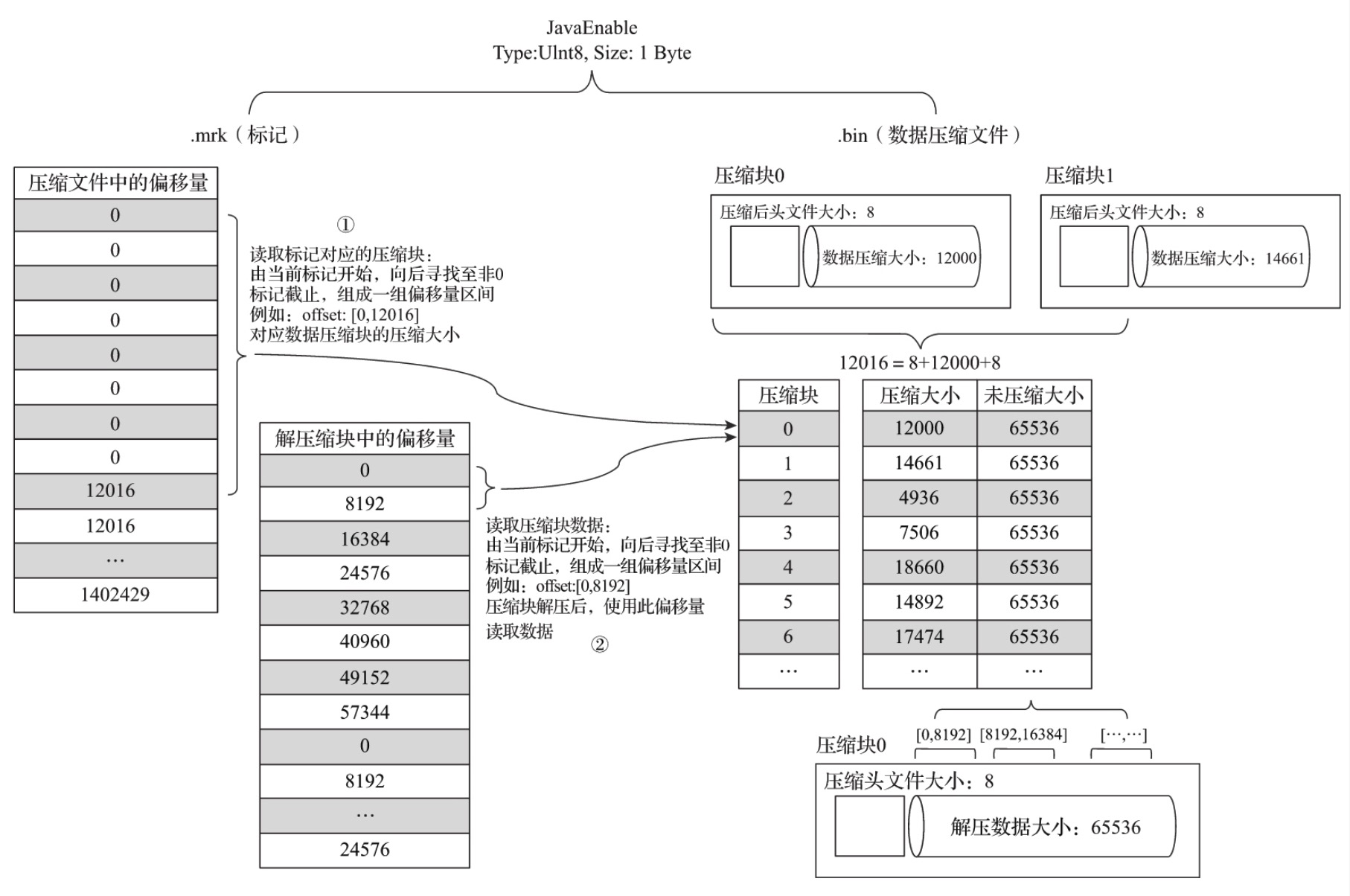
数据写入过程
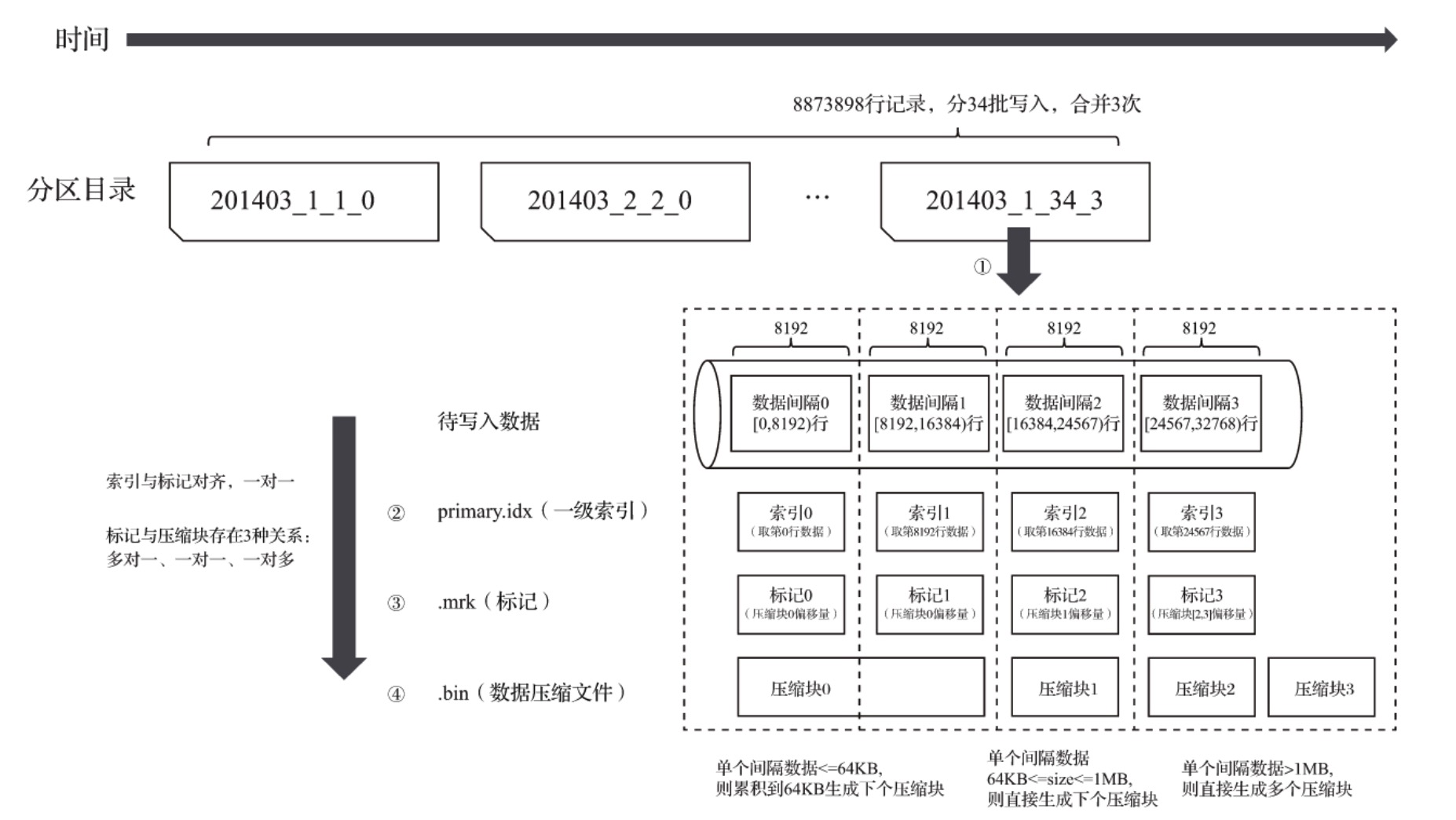
数据读取过程
MergeTree系列表引擎
ReplacingMergeTree
MergeTree拥有主键,但是主键没有唯一键的约束。ReplacingMergeTree的处理逻辑
(1) 使用ORDER BY排序键作为判断重复数据的唯一键。
(2) 只有在合并分区的时候才会触发删除重复数据的逻辑
(3) 以数据分区为单位删除重复数据。当分区合并时,同一分区的重复数据被删除,不同分区的合并数据不删除。
(4) 数据去重时,分区内的数据已经基于ORDER BY进行了排序,所以能够找到某些相邻的重复数据。
(5) 数据去重的策略
SummingMergeTree
在MergeTree的每个数据分区,数据按照order by 表达式排序,主键索引按照PRIMARY KEY表达式取值并排序。一般情况下,只需要定义ORDER BY即可。
SummingMergeTree和AggregatingMergeTree的聚合都是根据order by进行的。
如果同时声明了ORDER BY和PRIMARY KEY, MergeTree会强制要求PRIMARY KEY字段必须是ORDER BY的前缀。
处理逻辑:
(1) order by排序键作为聚合数据的条件Key
(2) 只有在合并分区的时候才会触发删除重复数据的逻辑
(3) 以数据分区为单位聚合数据。当分区合并时,同一分区的聚合key相同的数据会被合并汇总,而不同分区之间的数据不会被汇总。
(4) 定义引擎时,指定了columns汇总列,则sum汇总这些列字段;如果未指定,则聚合所有非主键的数值类型字段
(5) 汇总数据时,同一分区内,相同聚合key的多行数据合并成一行。其中,汇总字段进行sum计算,非汇总字段。使用第一行的数据。
(6) 之前嵌套结构,但列字段必须要Map后缀结尾。嵌套类型中,默认以第一个字段作为聚合key。除第一个字段外,任何名称以Key,Id,Type后缀结尾的字段,和第一个字段组成复合key。
没有设置了ver版本号,保留同一组重复数据中的最后一行
设置了ver版本号,保留同一组重复数据中的ver取值最大的一行
AggregatingMergeTree
AggregatingMergeTree 的order by,primary key同SummingMergeTree。
看下面例子
1 | CREATE TABLE agg_table( |
其中,列字段id, city 是聚合条件,等同于
1 | GROUP BY id,city |
code,value是聚合字段,等同于
1 | UNIQ(code), SUM(value) |
AggregateFunction是ClickHOuse一种特殊的数据类型,它能够以二进制的形式存储中间状态。写入数据,需要调用*State函数,读取数据,需要调用 *Merge函数
通常会使用MergeTree作为底表,存储全量的数据,并且新建一张物化视图。
1 | CREATE MATERIALIZED VIEW agg_view |
CollapsingMergeTree
对于ClickHouse这类高性能分析性数据库而言,对数据源文件修改是代价高昂的操作。相对于修改源文件,会将修改和删除转换成新增操作,以增代删。
CollapsingMergeTree定义一个sign标记位字段,记录数据行的状态。如果sign标记为1,是一行有效的数据。sign标记为-1,表示这行数据需要被删除。
1 | CREATE TABLE collpase_table( |
CollapsingMergeTree 同样以order by判断唯一性的依据。
(1)折叠数据不是实时触发的,和其他MergeTree变种引擎一样,这项特性在分区合并之后才会体现。分区合并之前,用户看到的是旧的数据。有2种方法解决:
查询之前使用
optimize TABLE table_name FINAL强制分区合并,但是方法效率很低改变查询方式
1
2
3SELECT id, sum(code), count(coude), avg(code), uniq(code)
FROM collpase_table
GROUP BY id改成
1
2
3
4SELECT id, sum(code*sign), count(code*sign), avg(code*sign), uniq(code*sign)
FROM collpase_table
GROUP BY id
HAVING SUM(sign) >0
(2)只有相同分区内的数据才能被折叠,
(3)CollapsingMergeTree对写入顺序有着严格的要求。如果按照正常顺序写入,先写入sign=1, 再写入sign=-1,则能够正常折叠。这种现象是CollapsingMergeTree的处理机制引起的,它要求sign=1和sign=-1的数据相邻,而分区内的数据基于order by排序,要实现sign=1和sign=-1的数据相邻,需要按照顺序写入。
如果数据的写入程序是单线程,可以控制写入顺序;如果是多线程,可以使用CollapsingMergeTree
Clickhouse的SQL语句查询

with rollup
rollup按照聚合键从右向左上卷数据,基于聚合函数依次生成分组小计和总计。加上聚合键个数为n, 最终会生成小计的个数是n+1。
1 | SELECT table,name,sum(bytes_on_disk) FROM system.parts |
最终的返回结果,附加了显示名称为空的小计汇总行。
with cube
cube像立方体一样,居于聚合键之间的所有组合生成小计信息。聚合键的个数为n,最终小计组合的个数是2的n次方。
1 | SELECT database,table,name,sum(bytes_on_disk) FROM |
with totals
基于聚合函数对所有数据进行汇总
1 | SELECT database,sum(bytes_on_disk),count(table) FROM system.parts |
参考文档
- 什么是ClickHouse
- ClickH原理解析和应用实践
我的公众号:lyp分享的地方
我的知乎专栏: https://zhuanlan.zhihu.com/c_1275466546035740672
我的博客:www.liangyaopei.com
Github Page: https://liangyaopei.github.io/